
在设计样本量的时候,研究设计者们似乎会有一些约定俗成的规则。例如,定量调研中每类人群的样本量要大于30,定性调研中每类人群样本至少3人。这些规定的数字是如何得来的?
接下来,我们就追本溯源,分别介绍一下,定量和定性研究中样本设计的原理。
1.样本设计的统计学基础
无论是定量还是定性研究,我们都是在用样本的数据来估计总体的情况,这被称为统计推断。而为了让收集的样本数据能够更加准确地推断总体情况,统计学中会对样本量有严格的要求。如果我们翻开统计学书中参数估计和假设检验这两章的内容,会发现每种不同的统计方法都会涉及到严格的使用条件,比如要知道总体是否服从正态分布,总体的平均数和方差是否已知等等。可是自然条件下的总体和样本,不可能全都服从某种统计学上有规律的分布,而且要在实际研究中直接获得总体的特征数据几乎是不可能的。
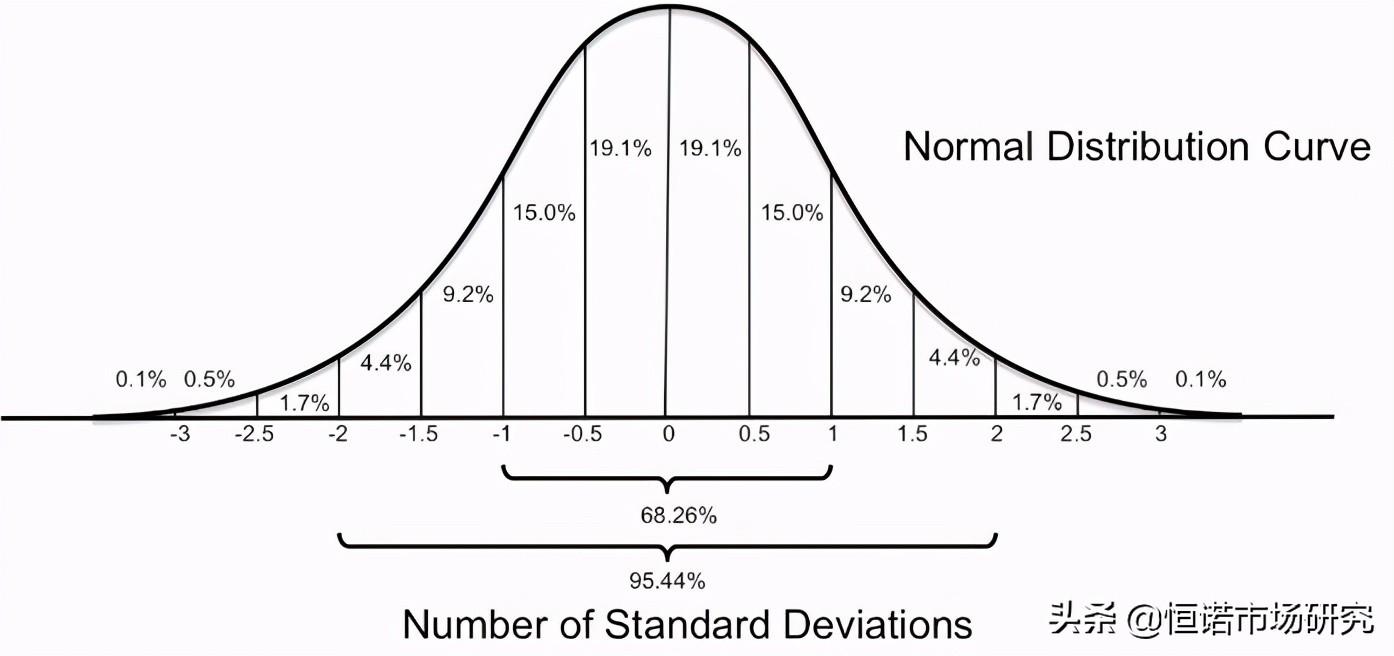
统计学和概率论中有一个十分重要的定理叫做中心极限定理,它指出了大量随机变量序列近似服从正态分布的条件。
中心极限理论样本量n足够大的情况下,总体的抽样分布会趋向于一个围绕总体参数平均值的正态分布,最终都可以依据正态分布的检验公式对它进行下一步分析。
在定量研究中,我们大部分情况下都会假定我们研究的总体参数是近似服从于正态分布的。因此,从理论上来看,样本量越大,我们获得的数据就越准确似乎是成立的。
2.定量研究的样本设计
对于定量研究中的样本量的计算,我们可以找到五花八门的计算方法,例如各类统计学书籍和统计软件中的计算公式和计算工具。在这些公式中,我们仍旧需要一些其总体参数来计算样本量。
以下举几个例子:
我们在问卷研究中常用到的随机抽样的样本计算公式:
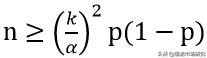
涉及到的参数有显著性水平α,临界值k,事件概率p。(《问卷统计分析实务》吴明隆)
来自于Creative Research System网站中的一个样本量计算工具:
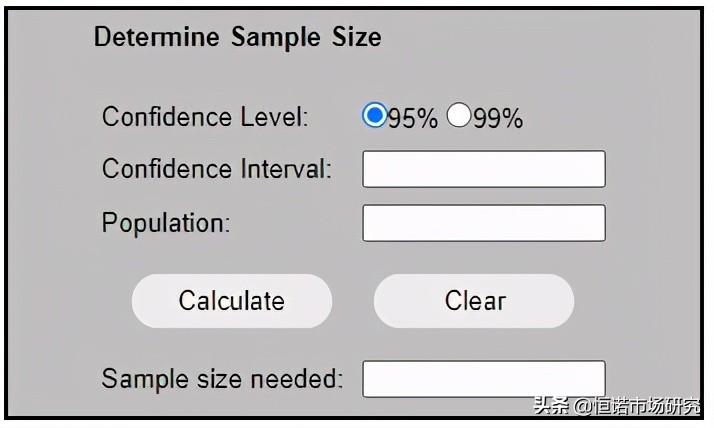
这个工具中所需要的参数有:置信水平(Confidence Level)、置信区间(Confidence Interval)和总体规模(Population)。
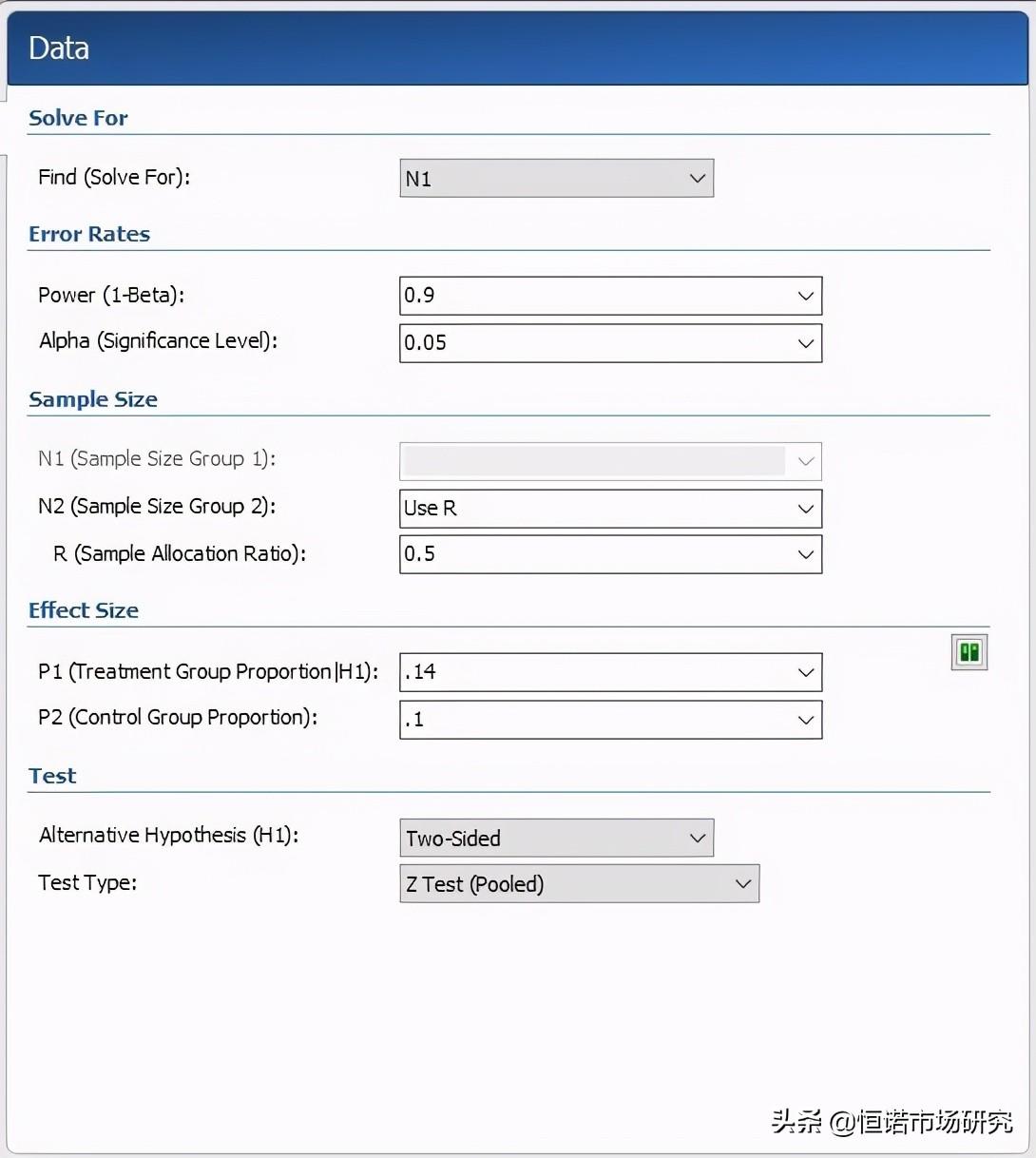
还有对数据要求更为严格的实验研究常用的软件PASS中计算样本量的工具:
这个工具根据所使用的不同实验方法来确定不同的计算方法,其中涉及到的常规参数有显著性水平(Significance Level,α),统计效力power(1-β)等。
在市场调研中,并不需要样本量达到我们做科研那样精确,计算样本量所需的参数值也很难直接从研究群体中获得精确的数值,所以,通常会根据统计学中的一些经验值规定,例如我们常用的显著性水平α=0.05。总结以上几类计算方法,我们不难发现,确定样本量中需要的最常见参数有:显著性水平、置信区间和置信水平。
置信区间是指由样本统计量所构造的总体参数估计的区间,展现的是这个参数的真实值落在测量值的周围的可信程度。例如,我们测量得出用户在进行某一操作的时长是1.05±0.05秒,就表示该操作时长的置信区间为1.00秒~1.10秒,那么真实的操作时长有多大的可能性是在1.00秒~1.10秒之间,则是由置信水平反映的。而显著性水平α是指的我们在假设检验中犯I型错误的概率,和置信水平之和为1。
统计分析中,通常会设置显著性水平α=0.05,置信水平为95%,若还以刚才的操作时长为例,意味着用户真实的操作时长位于1.00秒~1.10秒之间的可能性为95%。通俗点讲,0.05的显著性水平就表示我们抽样数据出错的概率为0.05,也就是我们通常所说的小概率事件。
设定好这些参数之后,我们先估计一下研究群体的总体规模,再利用相应的公式或计算工具算出调研所需的样本量大小。我们利用Creative Research System网站的计算工具计算出不同总体规模的样本量(α=0.05,置信区间为±5个标准差时):
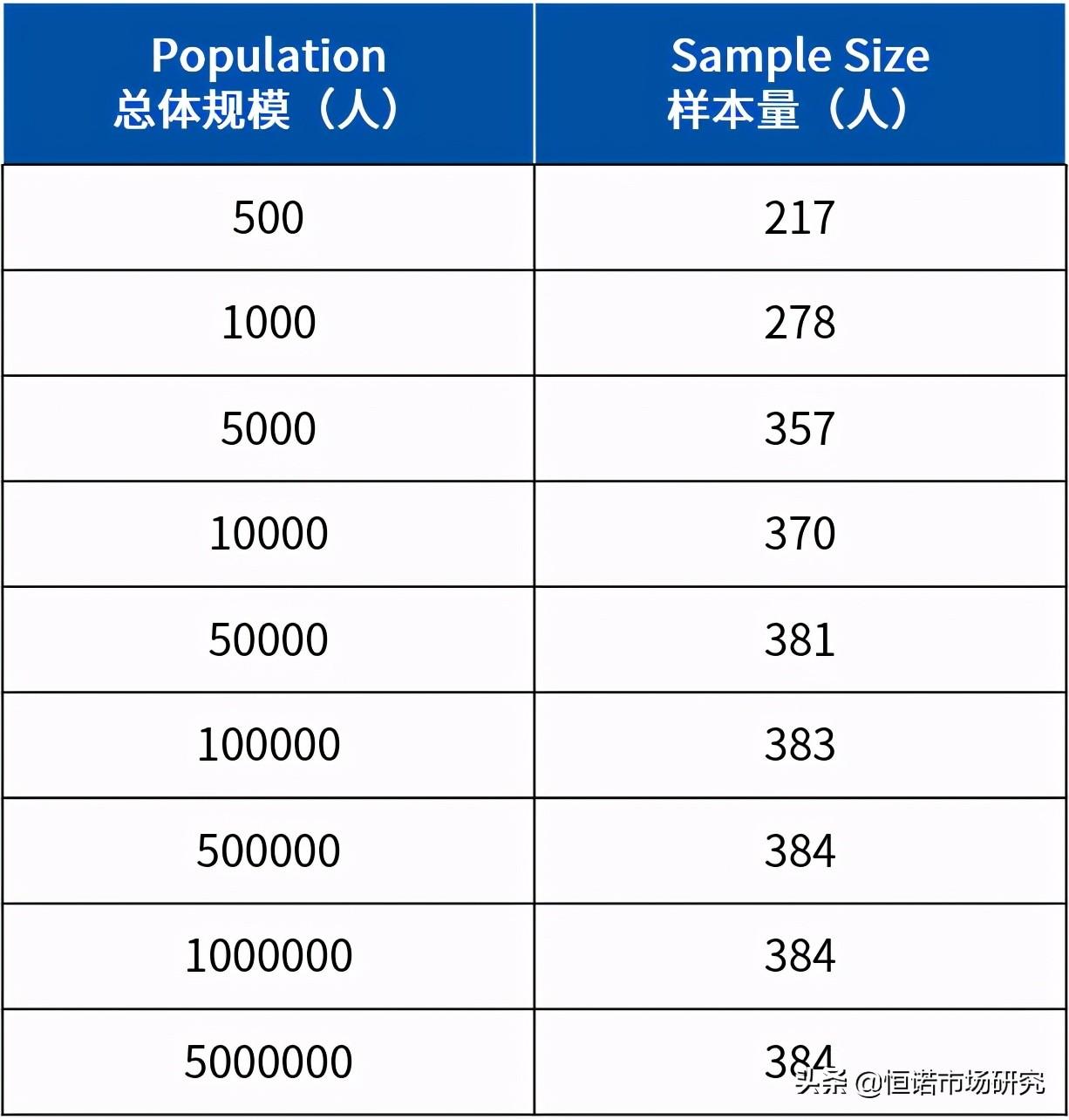
不难发现,当总体规模增大时,标准样本量并不是线性增加的,总体达到500000人以上时,标准样本量会在400左右的数值上稳定下来。所以,即使是一个用户规模上亿的产品,也没必要在一次研究中招募几千个样本。
3.定性研究的样本设计
与有着大量的统计分析技术支撑的定量研究不同,定性研究由于本身的调研目的是为了挖掘研究问题的深度,而非广度,对样本量要求的限制没有定量研究那么严格。定性研究的一个误区就是为了获得更多的样本数据和信息,而过多的追求样本量的大小。所以,我们在设计定性研究之前一定要有一个共识:定性研究获得的数据不具有统计学意义,它能帮我们发现一些具体现象背后的原因,或解决问题的启发性思路,而非广泛性的结论。
那么定性研究如何确定样本量呢?这个问题其实没有答案。定性研究选取样本的逻辑是达到数据饱和(信息饱和)为止,所以理论上,定性研究的样本量是做完研究后才知道的。而且根据定性研究的研究员挖掘数据的水平的不同,他们在一次研究中能获得的信息量也不同,达到数据饱和所需要的样本量自然也不同。所以在定性研究中,研究员更加依赖于自己的研究经验来设计样本数量。
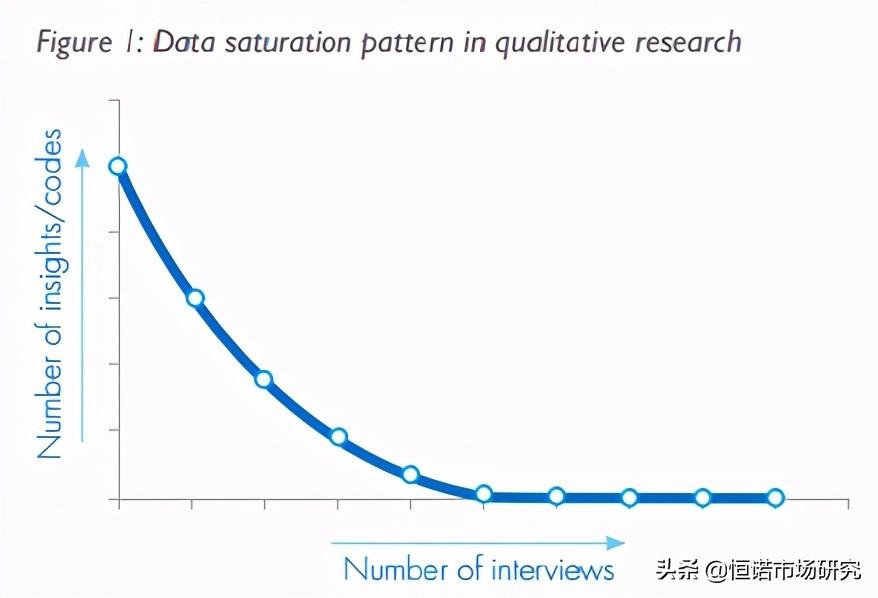
如下图(Qualitative market research: When enough is enough)展示了定性研究中样本量和获得数据量的关系:大部分数据来自第一个样本,之后的样本获得的数据会越来越少,达到一定的样本量后,就不会再获得新的数据,这便是数据饱和。
接下来,介绍一下市场调研公司Research by Design提出的定性调研的样本量的一个设计公式(Qualitative market research: When enough is enough)

样本量[N] =(范围[S] × 特征[C] )/专业程度[E] – 资源[R]
调查的范围
这是由你的研究目的决定的,你是为了对一个不熟悉的领域进行初期的探索性研究?还是对一个已上市的产品进行优化设计?如果是在进行一个初期的探索性研究,那就需要扩大你的调查范围;如果是要寻找目前产品中的优劣,那么你需要聚焦你的问题范围。调查范围可以是大于0的任何数字。
研究群体的特征
你需要对你的研究群体进行分类,确定本次研究的人群类别共有几类。在不考虑其他因素的影响下,行业经验通常认为每类人群达到信息饱和需要的样本量至少为3。因此,特征[C]=人群类别数×3。
研究员的专业程度
有经验的研究员比经验不足的研究员能从更小的样本量中挖掘更多的信息。对于专业程度的取值范围通常为1~2。
资源
这里的资源指的是你在本次研究中要考虑的时间和成本。事实上大部分的调研都会受到时间和成本的限制,而无满足的理论上的样本量设计,所以我们实际执行时的样本量只会比理想的样本量更少。
4.实际调研中时间和成本的考量
最后,我们来回答本文开头的几个问题:
调研中是不是样本量越大越好?
理论上的确是样本量越大获得的数据越具有代表性。但实际研究中,不得不考虑时间与成本的问题。例如,如果我们的研究人群渗透率低,招募被访者的难度也大,那么招募中的时间和人力成本就会相应增加,但调研的成本往往是在执行之前就确定好的,那么我们在设计样本量的时候,就会考虑到数据获取效率的问题。
在上文中我们也可以看到,无论是定量研究还是定性研究,样本量的增加和我们获取到数据质量提升并不是线性关系,盲目追求更大的样本量无疑是低效率的。“样本量越大越好”的观点在实际研究中是站不住脚的。
定量调研中每类人群的样本量要大于30,定性调研中每类人群样本至少3人。这些约定俗成的数字是如何得来的?
定量调研样本量的设计是基于统计学理论,我们在统计学中有一个大样本和小样本的概念,并认为样本量n≥30时,可称为大样本,(这个数字也是基于中心极限定理得来的,样本量大于30,抽样分布就基本接近于正态分布,但前提是总体分布正态,若总体分布不确定,临界值需要更加精确的分析),所以我们通常认为样本量大于30,是可以进行统计分析的前提。
定性研究中,依据数据饱和来确定每类人群的样本量,不同研究员的标准会不同,3人也是经过行业经验总结出的数字。
我们虽然说不需要更大的样本量,但也不表示能无条件地缩减样本量。因此,定量大样本中的30,和定性数据饱和的3都是一个底线临界值。

完结版小说''纹身送子观音,客人真怀孕了唐浩陈翠莲后续+第5章阅读
2025-09-12 01:00:55
博柜保险柜/全国各市服务热线号码实时反馈-今-日-更-新(博柜保险柜新保险柜打不开怎么办)
2025-09-12 00:00:04
科威顿保险柜售后服务热线号码-全国各售后号码实时反馈-今-日-汇-总(科威顿保险柜新保险柜怎么用)
2025-09-11 23:59:38
威斯顿保险柜-全国各售后热线实时反馈全+境+到+达(威斯顿保险柜保险柜报警了怎么办)
2025-09-11 23:57:05
悦倪保险柜售后24小时联系方式维修查询实时反馈-今-日-汇-总(悦倪保险柜迷你世界保险柜怎么用)
2025-09-11 23:55:53